
Hierarchical Reasoning Model assembly manual for toddlers
fun time for the whole family.


hello toddlers today we are assembling the hierarchical reasoning models by sapient intelligence step by step.
it’s a very fun kit you’ll see
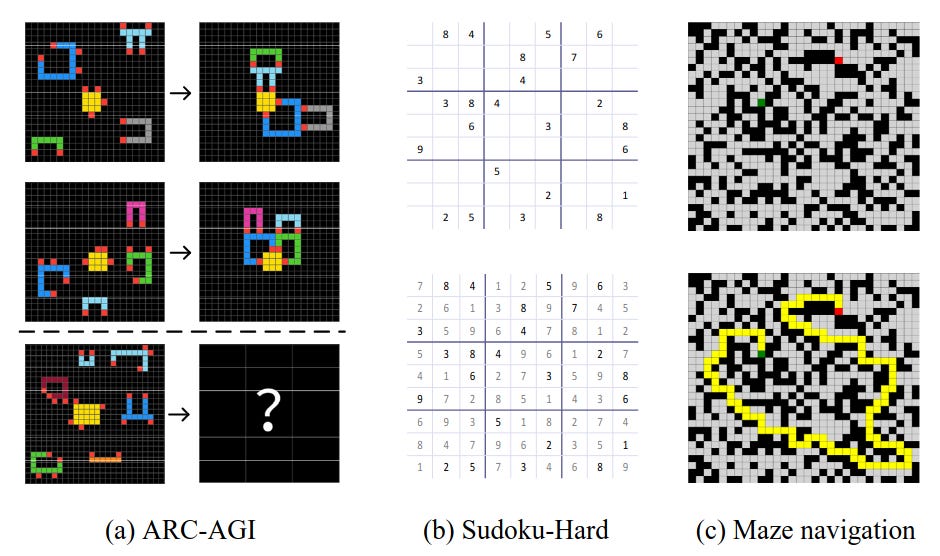
you will be able to use this architecture on all your favorite puzzles like:
your grandma sudoku
your dad sunday newspaper maze
your uncle francois chollet arc-agi 1 test sets
on the last puzzles set you can even get about ~37% of them correct in like 12h.
It’s great value for the price, but watch out kids some steps require adult supervision, so grab one of those.
also please don’t eat the puzzle embeddings at the end.
they are small and absolutely important (you can also choke on them so you are legally warned here).
⚠️ disclaimer for adults:
for a complete assessment of the HRM usefulness, do check out the full video by our collaborator Julia Turc:
step 0: get a 27M encoder block
first block you should reach out for is the encoder-only block which is about 27M parameters in size.
the block looks like the one on the left:
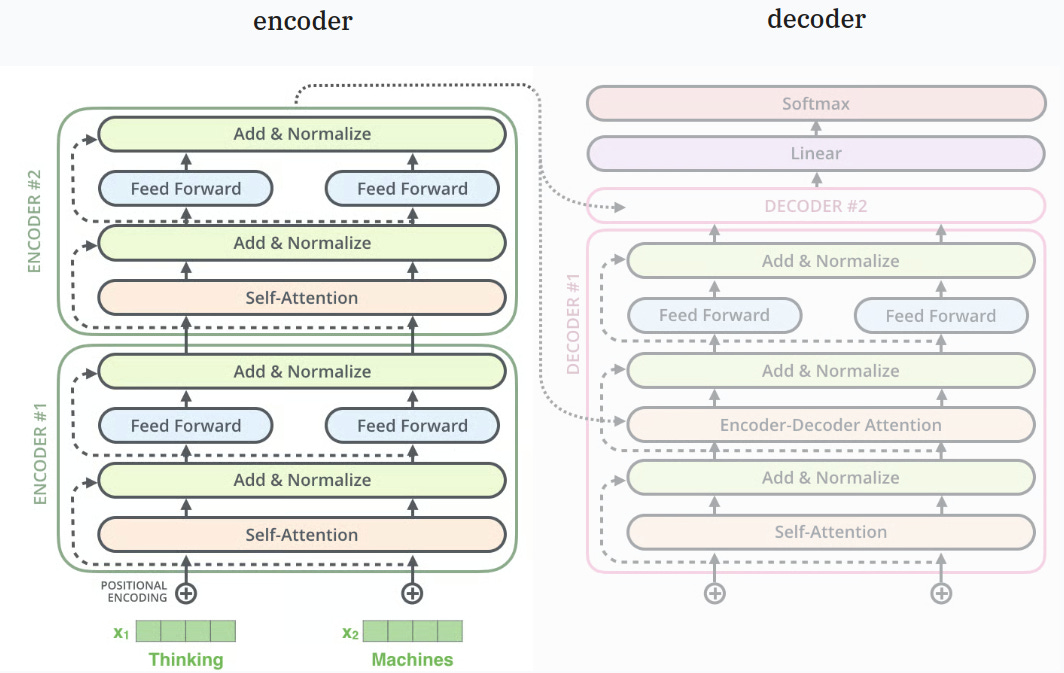
remember kids we are building a puzzle solving model not a language model (yuck).
those sucks kids, you hate them because they are ugly and pompous and really wasteful when you think of it.
if a language model was a thing, it would be a dictionary of the effective functions to recconstruct the humans representation of the world.
BOOOOOOORING bleh.
anyway, you are going to feed the full puzzle all at once and return it transformed with the proper solution added so no need for a decoder.
like this:
step 1: plug the 27M block to input and output source
now carefully plug the encoder with the input block and the output block like so:
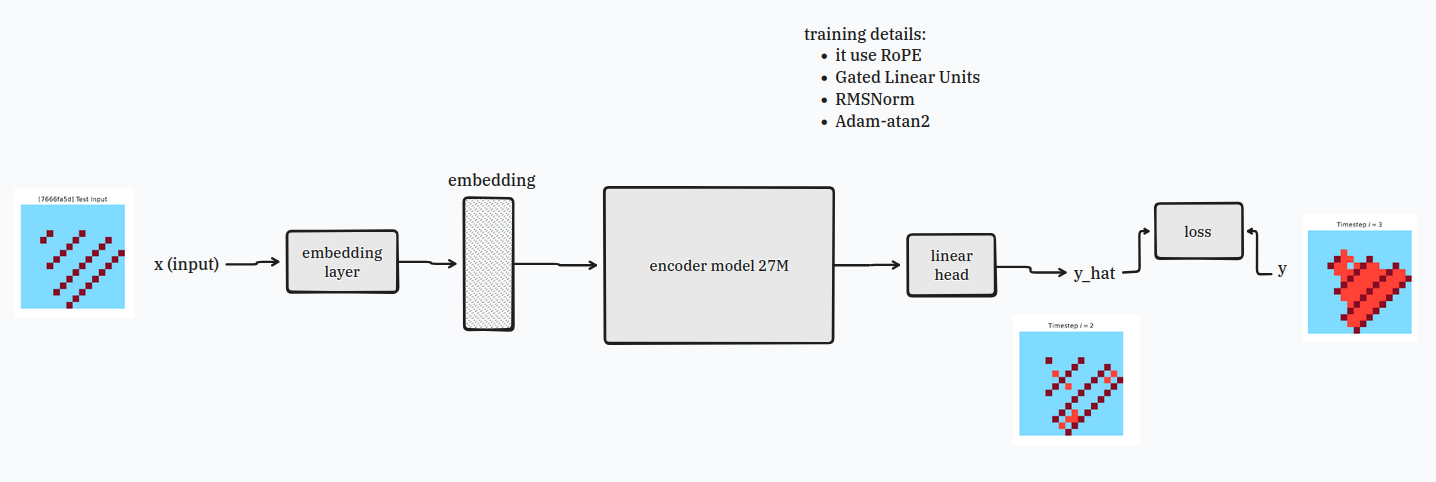
the input block will turn your puzzles into fun embeddings and the output block will spit out a solution for the puzzle the model is working on.
you can turn the power on and test it.
do notice how much the output puzzle kinda suck.
it’s because this 27M encoder model is fixed depth which is poopoo when dealing with puzzles that requires making mistakes and backtracking.
there is an easy fix for this.
step 2: add a latent recurrence wire
now carefully unplug the input and output block and add the thin latent recurrence wire.
like so, very simple modification:
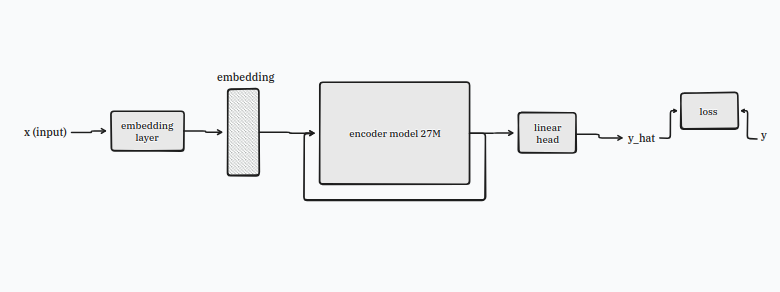
at first glance the wire might look like a chain-of-thought wire from these disgusting large-language-models. yuck no.
those are slimy and no good at all.
no no no my sweet child we are dealing with latent reasoning here.
this is pure, sweet, like the hug from your mom after coming back from school.
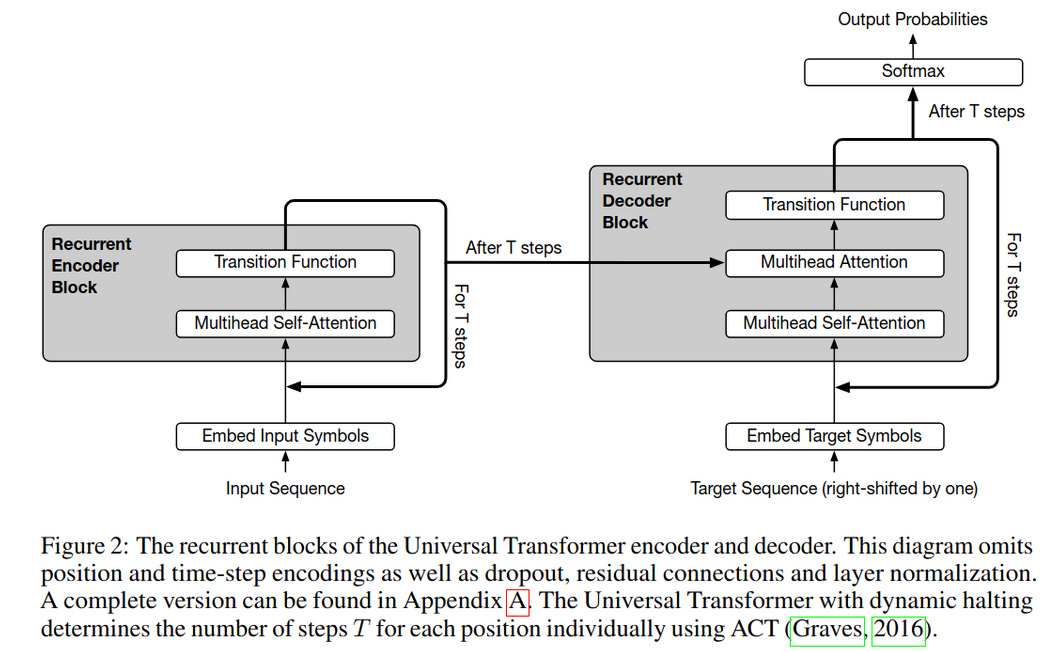
as a legal disclaimer we have to say that the HRM didn’t invent this latent reasoning and we can see the exact same pattern in the universal transformer.
adding this latent reasoning loop changed the architecture for one with fixed depth to one with variable depth.
the model can now technically loop however long it wants.

now test it. it’s better isn’t it? but wait…
oh no! this poor model got lost.
poor thing doesn’t remember what to do.
we can’t leave it like this, let’s help it out.
step 3: add a recall wire
models like this need to be told to always keep an eye on their original input.
so take the recall wire and connect it back to the model.
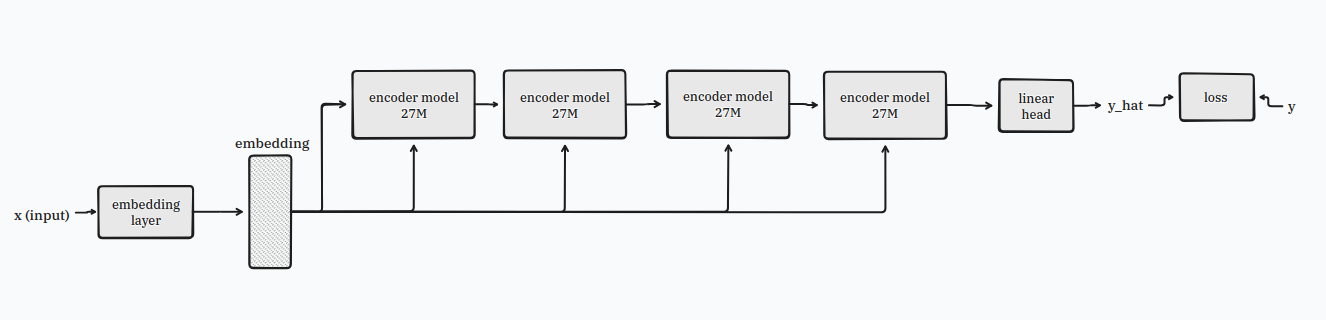
now this is called a recurrent network with recall and it’s a good thing.
but your mom didn’t buy you this kit to build a good model, she wants you to do great things ™️.
let’s look at rats.
step 4: rats and funny pranks
now listen close because this is important.
big important adult, which we call neuroscientists, had a job for rats.
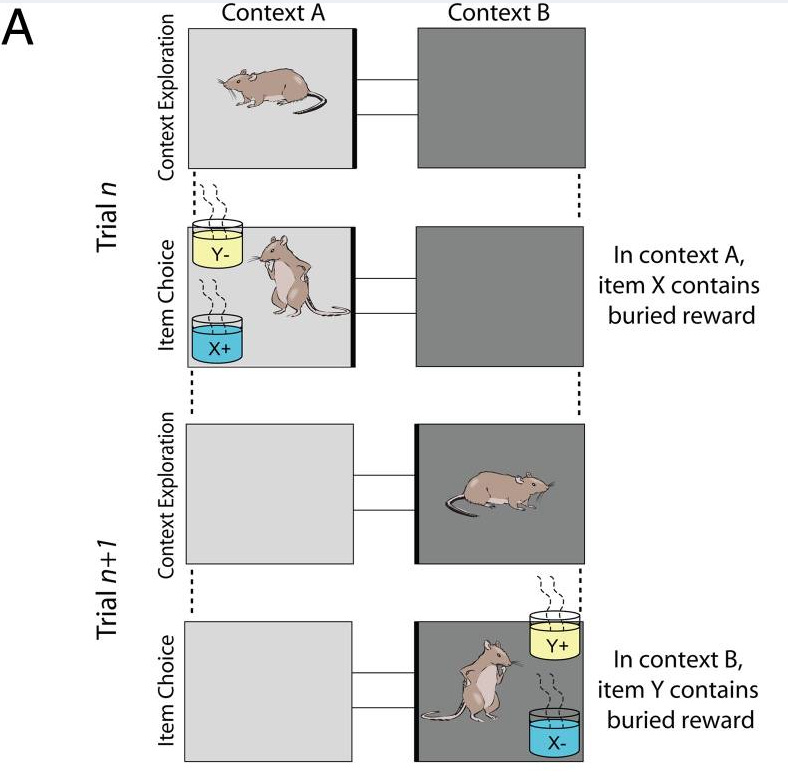
they gave the rats the task to find a funny surprise in two bucket in two different room.
the trick for rats was that the funny surprise was switched in the two rooms (what a funny little prank).
now, the neuroscientist weren’t just pulling the legs of the rat for fun, they had an important job to do.
they were secretly looking inside parts of the rat brain (called the hippocampus, looks like a seahorse yehaaaw) to see how the rat was learning about the prank.
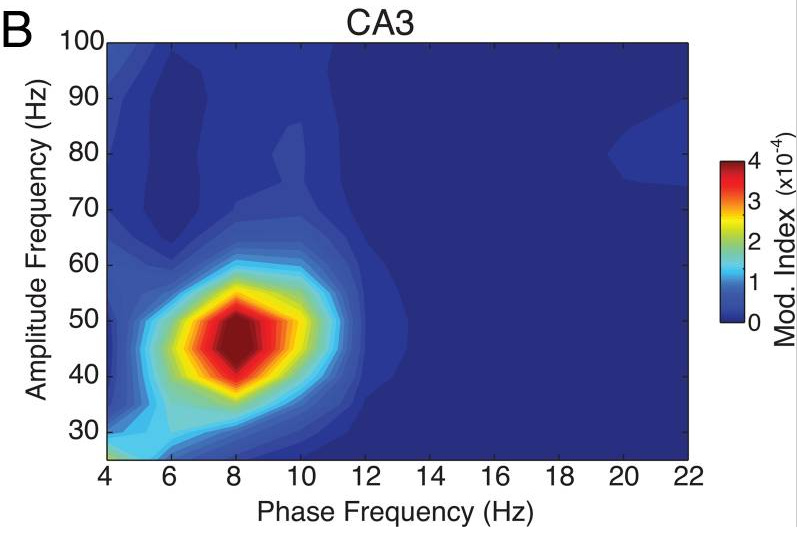
what they saw was that some parts of the brain were working and talking to each other to learn the trick!!!!:
some part were working rush rush rush because they were very busy and had lots of rapid information to handle.
other were working sloooooooowly like an old adult and helping the busy part get the work done.
this great teamwork made it possible for these poor little rat to not get too confused and understand the jolly-ol’ prank from these funny neuroscientist.
now we too love collaboration and working with friends.
let’s add collaboration to our model!
step 5: hierarchical reasoning
now, I will need you to take a deep breath and be big a big boy/girl ok?
yacine was pulling a little fun prank on you since the beginning (just like with the rats!).
we are going to remove some of the puzzle pieces we put in because they weren’t the right one to put in the first place! (oh no!)
don’t get mad, you will see it’s a good thing.
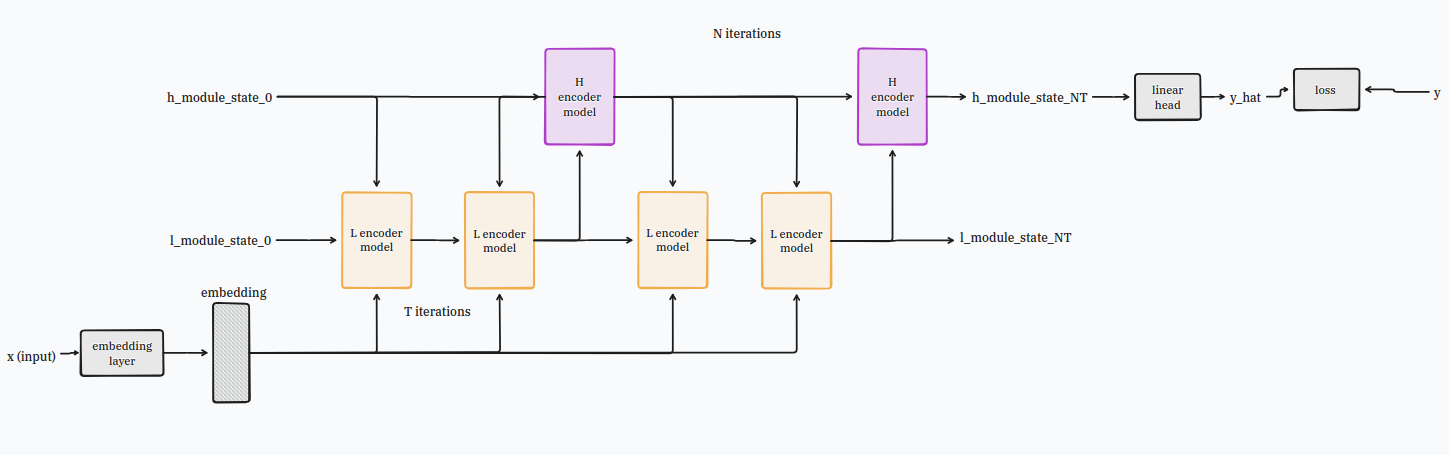
you will need to take two smaller identical encoder-only blocks and place them as follows:
one of the blocks needs to be wired in the input (with recall and recurrence wires); we’ll call this one low-level block
and the other block needs to be wired to the low-level block (with recall and recurrence) and to the output; we’ll call this one the high-level block.
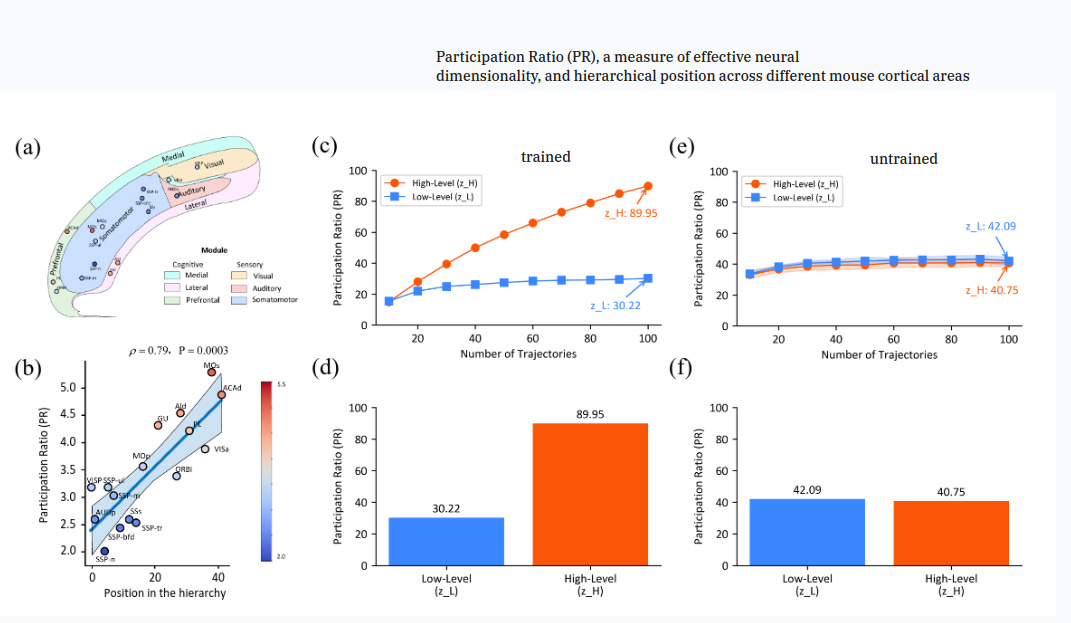
you might be a bit confused here, which one is my low level block and which is my high level block???
“IS THIS ANOTHER PRANK YACINE” I hear you say fist full of yacinego™️ block.
no my dear child, the blocks become a high or low level block because of the wiring!
the l module will be the one that will talk a lot, it will be recurring with itself T times before giving it’s work to the h module which will review it. the h module will then give gentle guidance to the l modules and it will do this N times.
in total now your model will talk and work in friendship on your puzzle N*T times.
good news also for your mom and dad credit card, you don’t need to run back-propogation-through-time with this model!
you can just use a one-step gradient at the very end of a N*T cycle!
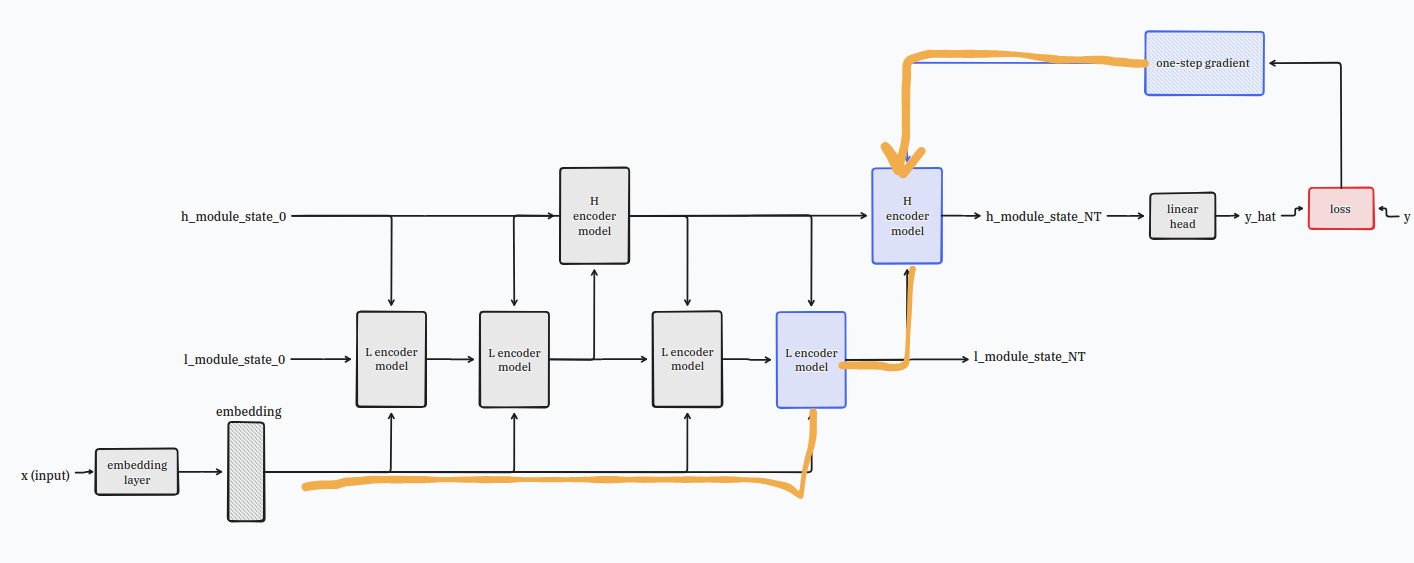
now, if you test this model on sudoku and mazes you might be a bit disappointed with the result.
we are missing an important element, let’s add it.
step 6: add outer loop wire
now carefully take two recurring wires from the kit and plug them as so:
plug one end on the h module end state to it’s starting state
and another one on the l module end state to it’s starting state
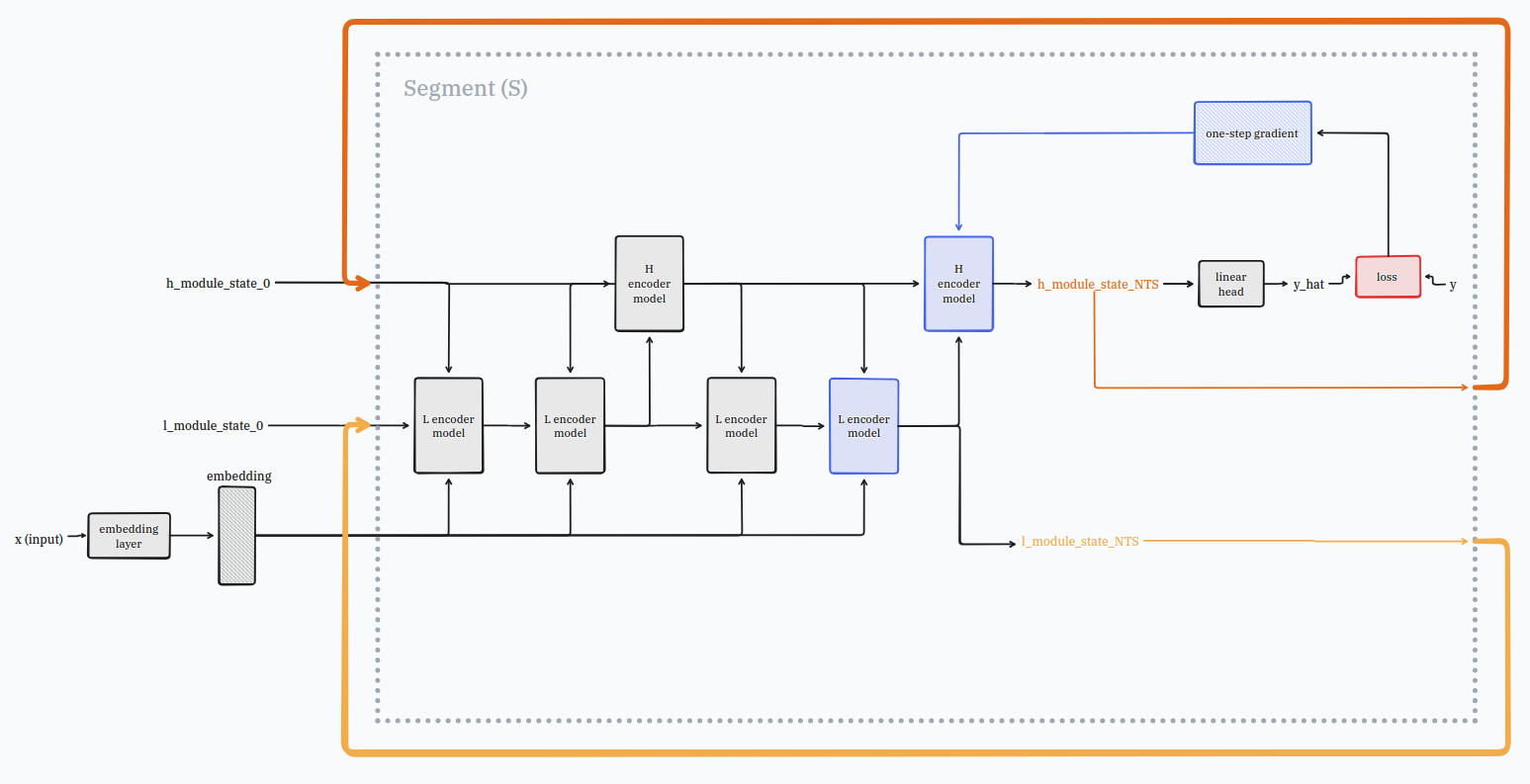
the model is now able to do something very important which is spend more time thinking about a problem.
kind of like when someone asks you a difficult riddle.
you don’t like to be rushed don’t you?
well the model is the same, he can now spend more time thinking on a puzzle.
but wait a second…
how long should we let the model think?
that’s where the road lights come in, let’s add them.
step 7: add road lights
take the tiny road lights, the one with the green and red lights, and plug it at the end of the model like so:
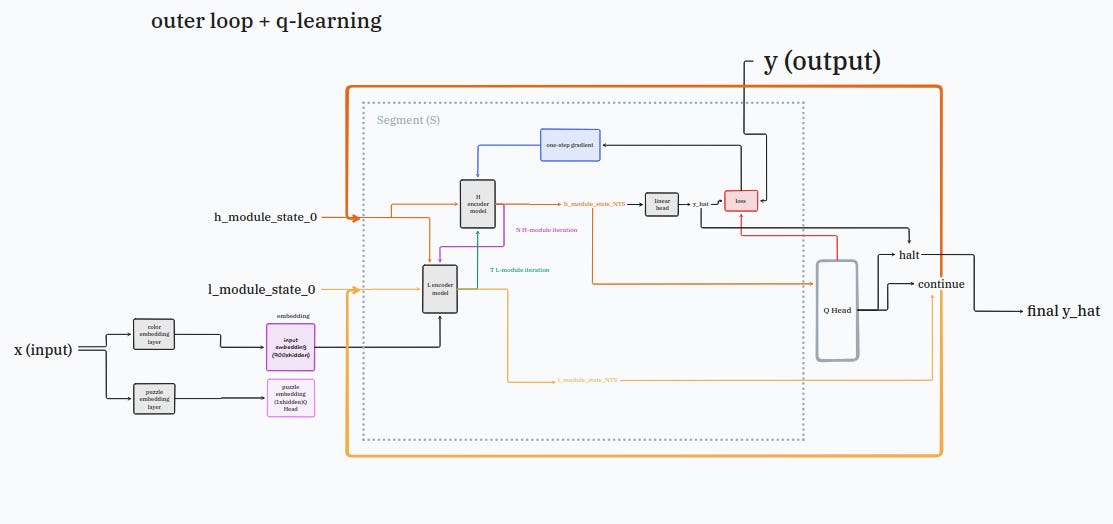
with this road light the model will be able to know when it’s time to stop thinking and when to continue for another cycle.
this way if it hits an easy puzzle it can do it quick quick.
if it hits a very difficult puzzle it can sloooooow doooooown and do a lot more thinking.
It’s great! It’s a good thing!
with the magic of reinforcement learning, it can even learn to use the road light on its own (just make sure to wire it to the loss properly).
now you have a very good model for your grandma's sudoku and your dad's sunday mazes.
but uncle chollet arc-agi puzzles are still too hard!
how come?
if you look carefully in uncle chollet puzzles set you see that he only gives you two example for each puzzle.
“JUST TWO??? NOT FAIR” I hear you say.
worry not my dear child, this trusty kit has got you covered.
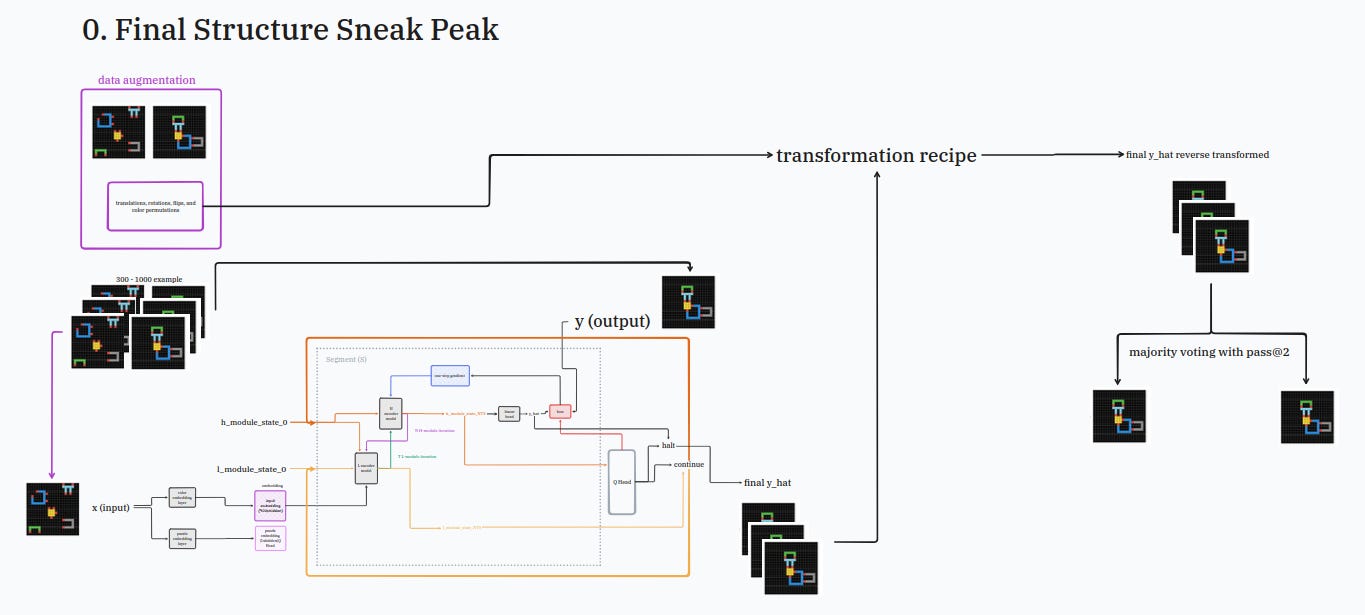
step 8: data-augmentation-framework™️
thanks to the data-augmentation-framework™️ you can turn any puzzles with limited instructions into a full dataset to train your model!
the only thing you need to do is to carefully lift and insert your HRM model into the provided case, like so:
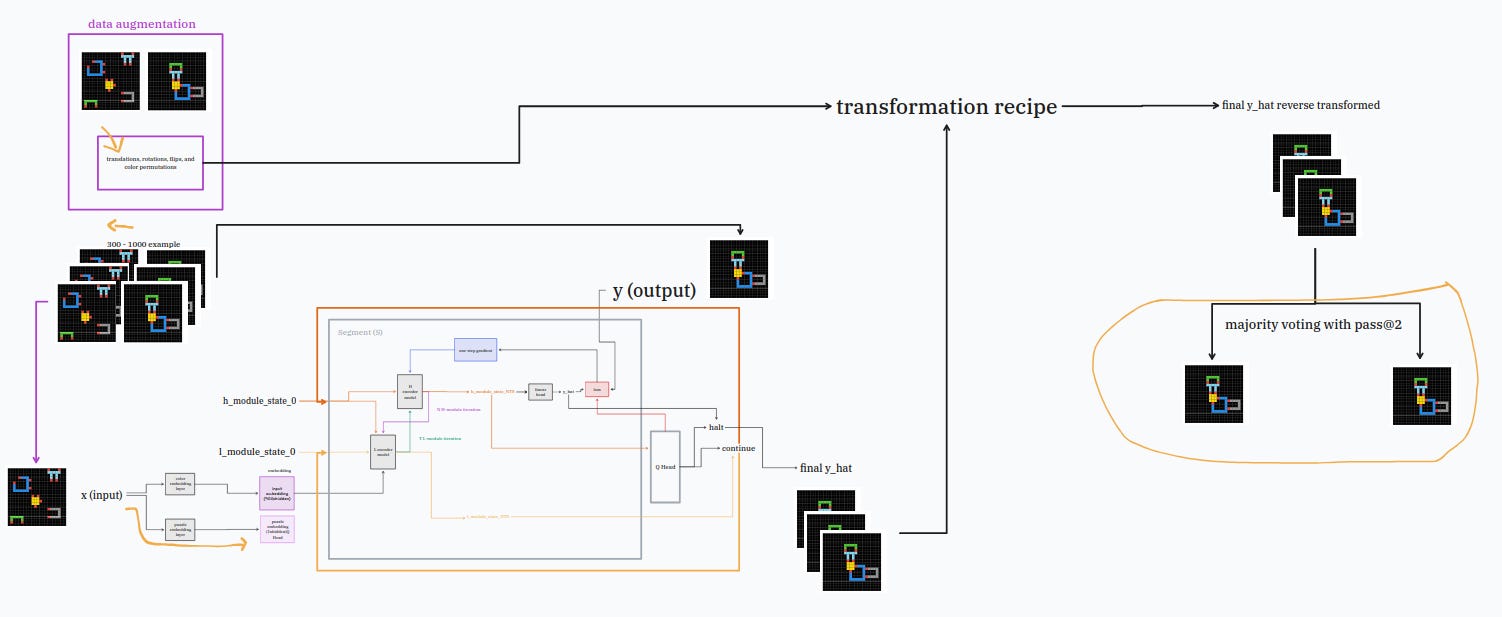
the data-augmentation-framework™️ works by taking your few examples and doing all sort of funny changes (300-1000 of them) like wiggling a bit the puzzles, rotating them, flipping and even changing the color.
how fun for the dataset!
after all these silly augmentations, the model will do the same but in reverse to clean up the mess a bit.
because at the end of the day, even if we had a lot of fun, we need to be serious and get the job done.
so it will take all of the possible puzzle answers and count those that look the same.
the two answers the model will have counted the most will be what we are going to give to uncle chollet.
legal disclaimer: the HRM didn’t invent the data augmentation methodology for arc-agi it was already tried in a previous network that didn’t use pre-training called compressARC
we are almost there kiddo, almost we just need one tinyyyyyy piece to make everything work.
step 9: the last piece of the puzzle
look into your kit, you should see one tiny tiny piece which is the puzzle embedding layer.
take this piece, resist the urge to taste it, and plug it right at the beginning where your input block is, like so:
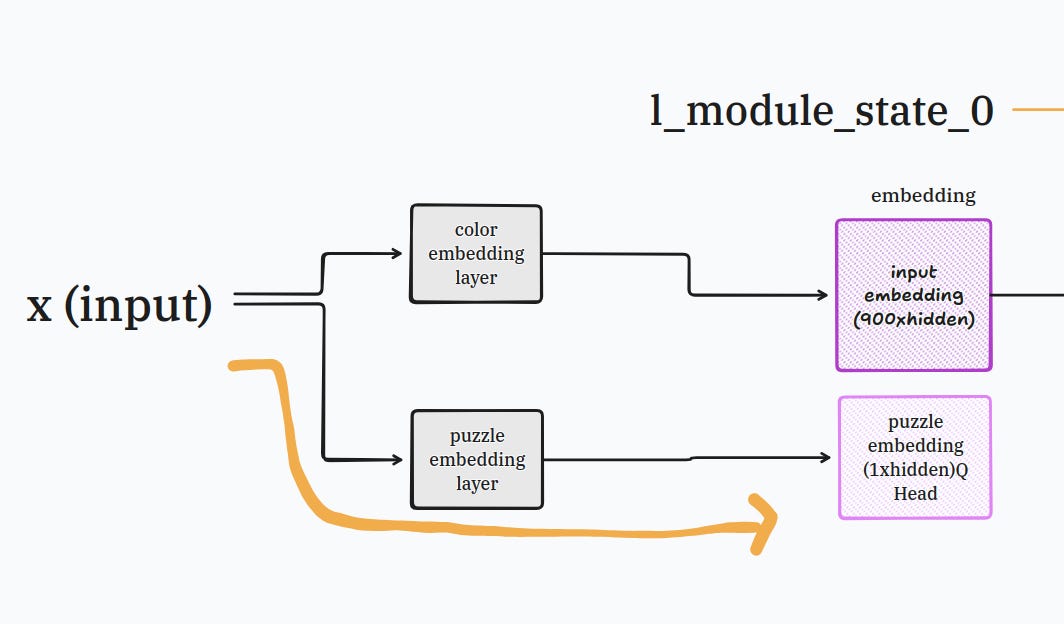
this tiny piece will take each transformation the data-augmentation-framework™️ has done on the arc-agi puzzles and will create a super duper secret name for it.
this secret name is very useful for the HRM model to understand what it needs to do, because remember this isn’t a bulbous disgusting hunk of language model junk (bleh bad bad).
this is a small and humble latent reasoning model; it needs all the help we can provide to do a good job.
nothing more nothing less, as our lord and savior intended.
and voila now with this kit you are able to solve all these puzzle!
how fun!!!!!!!!
don’t forget to ask your parent to get you the next yacinego kit, where we will add a moral judgment circuit into these disgusting language models!
Hey Yacine, love this explanation! It’s rare to see ML concepts explained through everyday objects we intuitively understand (like wires or traffic lights), but those associations really help understand the workings of ideas that seem abstract from a distance.