Generation of 3D Art with AI + Project Management in Data Science! 🗿
Generating art with AI is surprisingly easy! Here are 5 links to get you started!
Hi everyone! 👋
In the last newsletter I've presented in the extra section my latest AI generative art called "The Great Yolk Falls from Heaven" and a few of you wanted to get a bit more information with how it was generated.

The method used is a fascinating mix of deep neural network, art and dark-magic!
So in this newsletter I'll be covering some high level instruction on generating art like this, a few links to learn more about AI generative arts and some data science tips to improve your project management skills ✅!
Generating Image Through Text Prompt
The truth is I didn't do much. I simply followed these two steps:
- I prepared a neat text prompt of what I wanted the end-image to look like.
- I sent my text prompt to a CLIP guided diffusion neural network system!
Here, the text-prompt you chose is more dark magic than solid science since some keywords have unexpected effects on the end image! A good explorative mind is a must!
In this setup, the CLIP model from openai is used to guide another neural network to do image synthesis through multiple iterations of optimization.
CLIP looks at your text prompt and the generated image to figure out if they match well. Since CLIP has been trained on like the whole internet, it's quite good at figuring out the intent behind the image synthesis task.
A similar type of system could be used to do something even more wild...
Generating 3D Meshes through Text Prompt!
So if you push this idea further, you could generate 3D object based only on a well-crafted text-prompt!
I've stumbled onto this paper that does almost that, the neural network system stylize a base 3D mesh to fit the style of the input text!
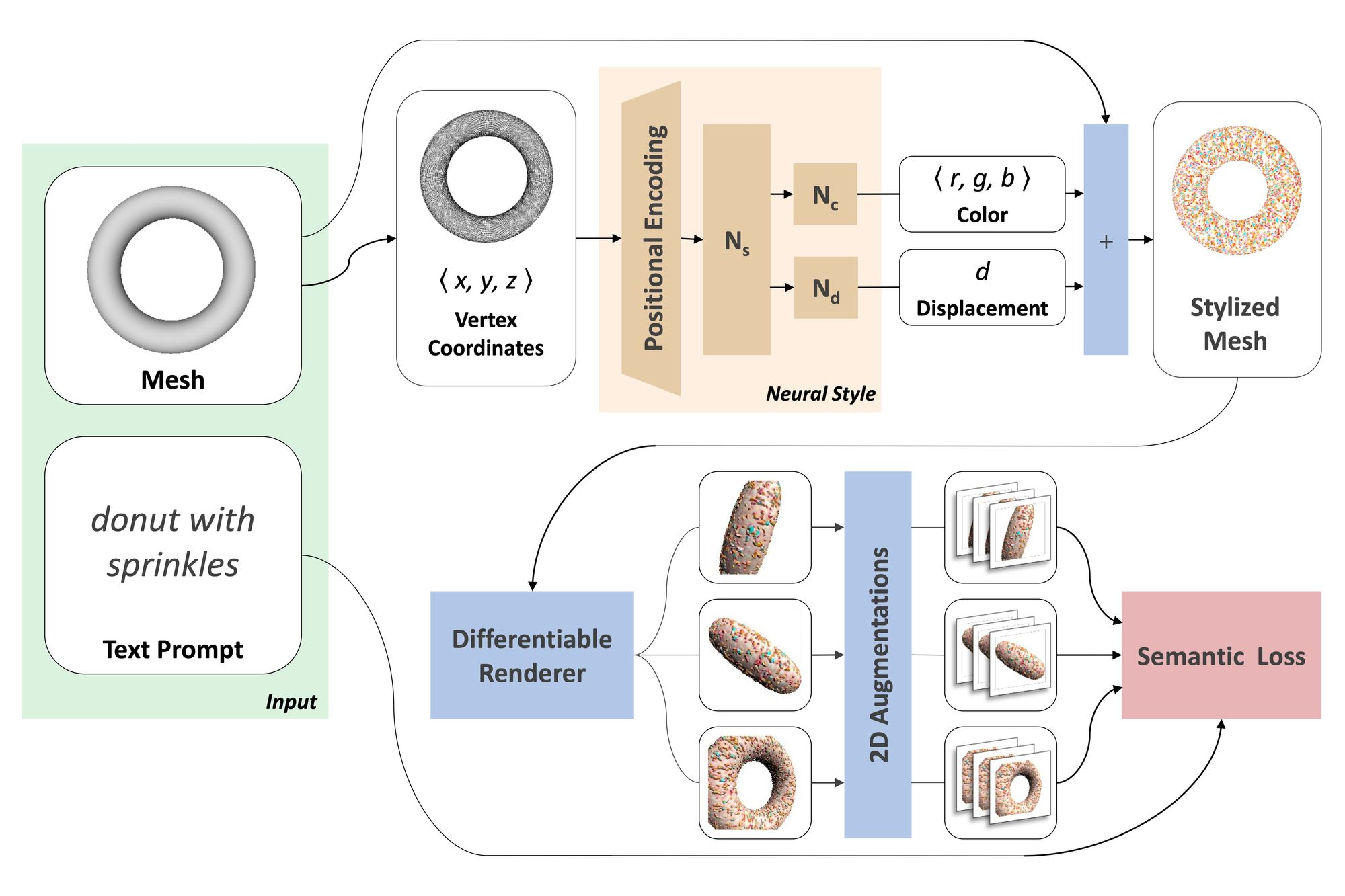
I'll make a full tutorial on these two type of art-generation method at the theoretical and code level on my Youtube channel in the next weeks!
Meanwhile here is what happen when I tried to stylize the humanoid base mesh with the "Ash Ketchum from Pokémon" prompt 😅!

The technique is very similar to the CLIP + guided diffusion system. The core idea in both of these system is that an NLP system that understand images is used to guide another generator network. It's beautiful!
Useful Machine Learning Resource on Generative Art! 🎨
There is a lots of great resource out there in this nascent field of AI Driven Generative Art. Here are a few links to get you started on your artistic journey along with some code sample to create right away!
- Generates images from text prompts with CLIP guided diffusion: Full notebook walking through how to generate an image similar to The Great Yolk Falls from Heaven.
- Kaggle Notebook Implementation of Text2Mesh: Text-Driven Neural Stylization for Meshes: I've used that to generate the "beautiful" rendering of Ash!
- Blog post from openai on CLIP and original paper submitted to arXiv : Both the blog post and the paper are a nice read. A good demonstration of what previous work unlock in term of creativity potential!
- Rivers Have Wings Twitter account: This is the twitter account of the person who created the CLIP + guided diffusion notebook and a good source of inspiration for AI/generative art! She also usually gives out her text-prompt used to make the images, which help in the exploration phase!
- Neural Style Transfer : From Theory to Pytorch Implementation : This is a full tutorial on another type of creative use of neural network to take the style of one image and apply it to another image. The technique covered is much less black-boxy than the system I've shown in the introduction, but also a bit primitive!
I love that kind of art, if you have a link to share related to that don't hesitate to send it my way at mail@yacinemahdid.com!
Data Science Tips: Document and Fact Check All Assumptions
In all data science project there is a big foundation of unknown and not-100%-proven assumptions that are put in place in order to get the project started. These assumptions are crucial to set up in order to get somewhere in the analysis.
Open any research papers and look at the limitation section and you will usually see some of them being spelled out. However, these assumptions aren't always properly documented and usually lead to much of the big time sinks in a research project.
Sometime, underlying assumption don't hold anymore with the new findings you gleaned out of some exploratory data analysis meaning that if you don't know about some assumption, you might work your way through a scientific dead-end.
Therefore, one tips I give to make sure that you have a good visibility on this foundational layer of unknowns is to document them early on.

Type of Assumptions
There are two main type of assumptions in a data science project:
- Your own assumption that you build up during your project.
- Other assumption that are already there when you began your project.
The first kind isn't too problematic. Most data scientist will naturally document why they did this or that in their project. Whether in their analysis or in a report, it's just natural. Yet, there should always be a constant effort to continue documenting them even when the analysis project stretch in time. As a rule of thumbs, if you can't write your limitation section in an hypothetical paper easily with your documentation, it's incomplete.
The second type of assumption that came before you start the project are the most important ones to watch out for. They are often completely overlooked or difficult to distinguish from basic facts. This is one of the reason why it is so crucial to ask a heck load of question before even starting any project.
Even statement about the usefulness of the project or the expect impact should be documented and fact checked.
Benefits
Having this proper mapping of assumptions in place and reviewing them periodically will unlock two things:
Allow you to control the project better and to steer it in the right direction 🛺
If you know what your assumptions are and they are documented, you will be much more confident to call the shots for the next steps in your analysis. Worst case, if the next step is a bit of a theoretical stretch you only need to document the assumption you made and move on.
This put the control of the project in your own hands and make everybody else a contributor (even your team-lead, PI or boss) instead of the opposite.
Allow you to raise flags fast if an assumption is proven incorrect throughout an analysis. 🚩🚩🚩
If there was an assumption that was made early on, even before the project was given to you, and it is proven to be wrong it can be catastrophic if you have no idea about it.
What usually happen if you are in the dark is that you will work your way towards the void, erroneous results or incomprehensible ones. This is a very stressful situation to be in because you will be reporting these results to your manager and what usually ends up happening is they will say something along the line of "you must have made a mistake, recheck your code". So you will recheck it and get even more stressed out and paranoid that you messed up something.
While if every assumption was already documented, your first reaction will be to double check if all assumptions are still holding and if they are not this is a flag you raise and you can start working on your analysis from there!
Conclusion
Applying this layer of documentation in your work will instantaneously make you a much more effective data scientist! Furthermore, it will make your results interesting to debate and discuss since you are well aware of the underlying assumptions holding everything together.
Validating or disproving these assumptions is what leads to the subsequent data science project and continue the cycle of research towards more discovery!
I hope this newsletter content was useful! For more machine-learning content do check out my Youtube channel covering code and theory!
Have a wonderful week everyone! 👋
Extra: Job Posting for Senior Machine Learning Engineer
I'm currently hiring at my company for an experienced Senior Machine Learning Engineer. If you have a good experience in that area or know someone, send out an email to my head of product at hamad@axya.co! 😃(if you are unsure if you qualify as senior just apply, I'm looking at all CVs so I'll be able to ping you if you would be better fit in another posting)!
