005 📧 - Are AIs model becoming sentient?
AI's are making waves once again fueled by consciousness claim hype. Before we head into another AI winter, let's try to reduce the hype (just enough to still get funding and calm everyone expectation).

In today's issue, we will talk about the state of the AI systems that can generated content and if they are becoming conscious.
TLDR: No current AIs like LaMDA/GPT-3 are not sentient in my opinion, they have very good mapping of the concept composing the human world and it's the interaction with that good mapping that is fooling users.
Current State
Big language models are getting increasingly good at generating output that are difficult to tell if they come from an human or not.
Their content generation dominance is seen in different modality like text conversation, images and even code.
In all these different output type, the core of the intelligence is powered by a huge language model trained on big big text-corpus (like sometime the whole visible internet).
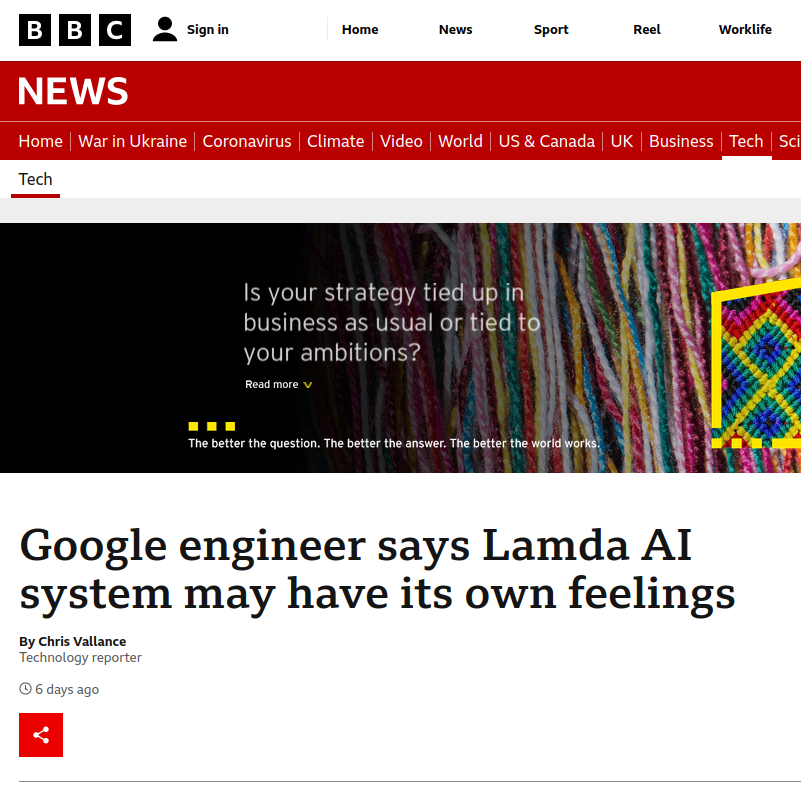
One stark example of how good these models are at generating human-like content has been on display recently. You might have heard the news of a google engineer that was so spooked chatting with an AI called LaMDA that he decided to alert media outlets that it was conscious.
The language modelisation on these models (and by extension their mapping of the world) is so good that it is indeed very convincing that you are dealing with something more than a computer program.
Yet, going as far as saying that they are conscious is a bit of stretch.
Let's look at a three example to illustrate why sentience discussion are a bit too pre-mature.
Pre-face
Let's just pre-face the discussion of the following three modality by the fact that the models behind these AI system are mind-bogglingly enormous.
For instance, GPT-3 (a language model) has 175 billion of parameters. If you are a machine-learning practitioner you already know that there is a lot you can do with a multiple linear regression with like 40 parameters. It's difficult to grasp how much capacity such a model has.
Furthermore, the amount of data that is needed to train model of this magnitude is also out of this world. We are talking about 500 billion of tokens of billions of pages which amounts to hundred of terabytes of training data. Meaning it has seen A LOT of things, more than many humans can ever read in their lifetime.
So keep that in mind while looking at result from these systems.
Text Message
In the text modality, there are many potential tasks that can be achieved by the AI system:
- prompt completion
- Q&A
- general conversation
- reasoning
The google engineer in question got spooked principally because he was conversing with the model and asked questions that it answered.
One glaring issue with these system with respect to conversation is that they don't have long term memory. They are kind of frozen in time.
What is happening when sending a message to such a system is more similar to querying a weird-organic type of database. As can be seen in this re-tweet by Yann LeCun Chief AI Scientist at Meta:
Haha!
— Yann LeCun (@ylecun) November 1, 2020
At least GPT-3 isn't bad at paraphrasing what it just read. https://t.co/GMrzicrBQU
In the above example, the model was seeded with the following text from Yann LeCun and then asked afterward the question containing the words What does Yann LeCun think of GPT-3?:
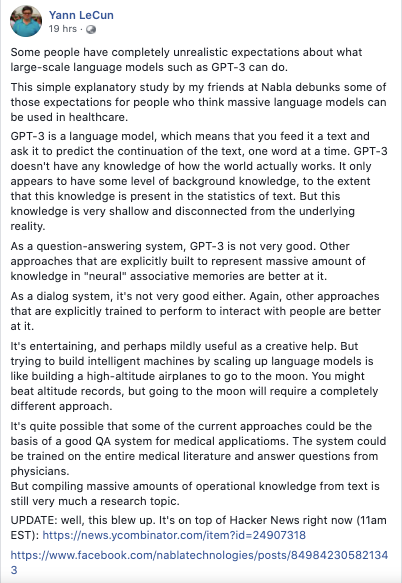
Which yielded a paraphrased compilation of the message above. The model do have a good mapping of language and how some tokens link to other tokens statistically. However, it seems that it's parroting a compressed version of what it just saw.
Here are some more text example that show how that specific model crumble when asked reasoning questions from MIT Technical Reviews (normal font is the prompt and bold is what GPT-3 completed):
At the party, I poured myself a glass of lemonade, but it turned out to be too sour, so I added a little sugar. I didn’t see a spoon handy, so I stirred it with a cigarette. But that turned out to be a bad idea because it kept falling on the floor. That’s when he decided to start the Cremation Association of North America, which has become a major cremation provider with 145 locations.
This is either non-sense, a direct quote from a new Lynch movie or the AI agent that is playing with us.

One of the reason why it might generate such a non-nonsensical prompt-completion might be that the input is too narrow for the model internal mapping. Meaning that there isn't much training data seen that match this sort of statistical arrangement of text.
The model most likely took whatever mapped closer to the prompt, which to us human don't look that it is following a train of thought that is coherent.
It's hard to untangle the intent behind a prompt completion or a conversation response since the measure of success is ambiguous. For instance if the output is not matching what you are expecting, does it mean that the AI is not conscious or that it misunderstood what you wanted?
In the next modality, we will explore a less ambiguous example which shows what happen when the mapping is straightforward with the training data because of a too-narrow prompt.
Code
Github Co-pilot is an interesting AI system that use under the hood GPT-3 and Codex (a descendant of GPT-3). Basically what it does is that given a prompt, it can generate working code.

The underlying model is the same that we've discussed in the text modality so doing this code-generation task gives us a very good glimpse at what is going on behind the scene.
Let's look at one glaring example of a naked direct mapping from prompt to training data:
I don't want to say anything but that's not the right license Mr Copilot. pic.twitter.com/hs8JRVQ7xJ
— Armin Ronacher (@mitsuhiko) July 2, 2021
The output shown above is direct a regurgitation of some function seen in Quake 3. This function was part of the training data.
Since there is no wiggle-room for interpretation, it's easy to see how the model mapped directly to the existing source code it trained on.
This shows that the AI is much more akin to a compressed organic database than a conscious agent.
Let's dive deeper on what is happening when we modulate the input prompt and we'll illustrate how these AI system behave like a good-old-boring search engine thanks to AI artists.
Images
You might have heard of DALL-E (1 and 2) and Imagen; Using big big language models like GPT-3 under the hood they are able to take a prompt and output an image that kinda-look like what the prompt is asking.

It's very interesting to check what the researcher shows as an example prompt:
An astronaut riding a horse in a photorealistic style.
The output shows that the AI system has a great comprehension of the world because it is coherent with the prompt used!
However, AI artist are not using these systems with such clean prompt. How they are interacting with them looks more like how a power-user of a search engine would put keywords together to navigate more effectively the search-space.
Here are two snippets from an interview with an AI artist called zenElan on his creative process:

NC: Are there any tips/tricks you’d like to give artists just starting out on NightCafe or AI art in general?
ZE: Adopt the position of learning a new tool. It's common to start by randomly throwing words together just to see what comes back which is a great place to start, but if you want to go deeper recognize that you have an incredibly powerful tool in front of you. The basic modifiers that are provided are great entry point. Learn what works and why. Recognize the changes by adding just one modifier. Keep creations simple, subject matter + style. Then start combining modifiers knowingly. Eventually throw an artist into the mix, like "Thomas Kinkade" or "James Gurney". Once you add artists, new worlds become available. Then start combining artists… that’s where the fun happens.
[...]
NC: What are some of your favorite modifiers to use in your text prompts? Why?
ZE: I used to be a photographer so find myself playing with modifiers as if playing with photography gear. "Bokeh" provides depth and "panorama" is like a wide angle lens. If too wide I drop the weight as if changing the "focal length" of the lens. Even "telephoto", "fisheye lens" and "time-lapse" works. "Colorful" is great, but even better specifying a color palette, "Colorful, mostly reds, purples, blues and black". “Hyperdetailed” often returns creations looking as if they are already upscaled, though if a creation comes back too “noisy”, the modifier “cel-shaded” or “polished” with a low weight cleans things up nice. Some favorite combinations that are fun to play with are “art nouveau rococo architecture” & "film noir, synthwave, glowing neon". Lastly, when in doubt... "eldritch". It works every time. It's interesting to approach AI art with both what you see and how you see it.
This feels more like someone showing out all the shortcuts he use in Adobe Photoshop than someone telling us how they are conversing with a conscious entity.
It's also not uncommon to have a whole bunch of operators chained together like this: "beautiful couch in the style of {artist} | unreal engine | high resolution | ...". Which are laughably effective in generating great art-piece.
Conclusion
To conclude this brief exploration of sentience in language system, I make the final claim that they are most likely not conscious.
They have a very good mapping of their gargantuesque input datasets and that logical mapping reflect how humans think about the world through the lens of language. Yet, we wouldn't say that a database with a good search function is conscious.
I'm sure that a good mapping of the world is required for consciousness to be able to manifest itself in a way that is understandable by human. However, the mapping alone is not sufficient!
Resource
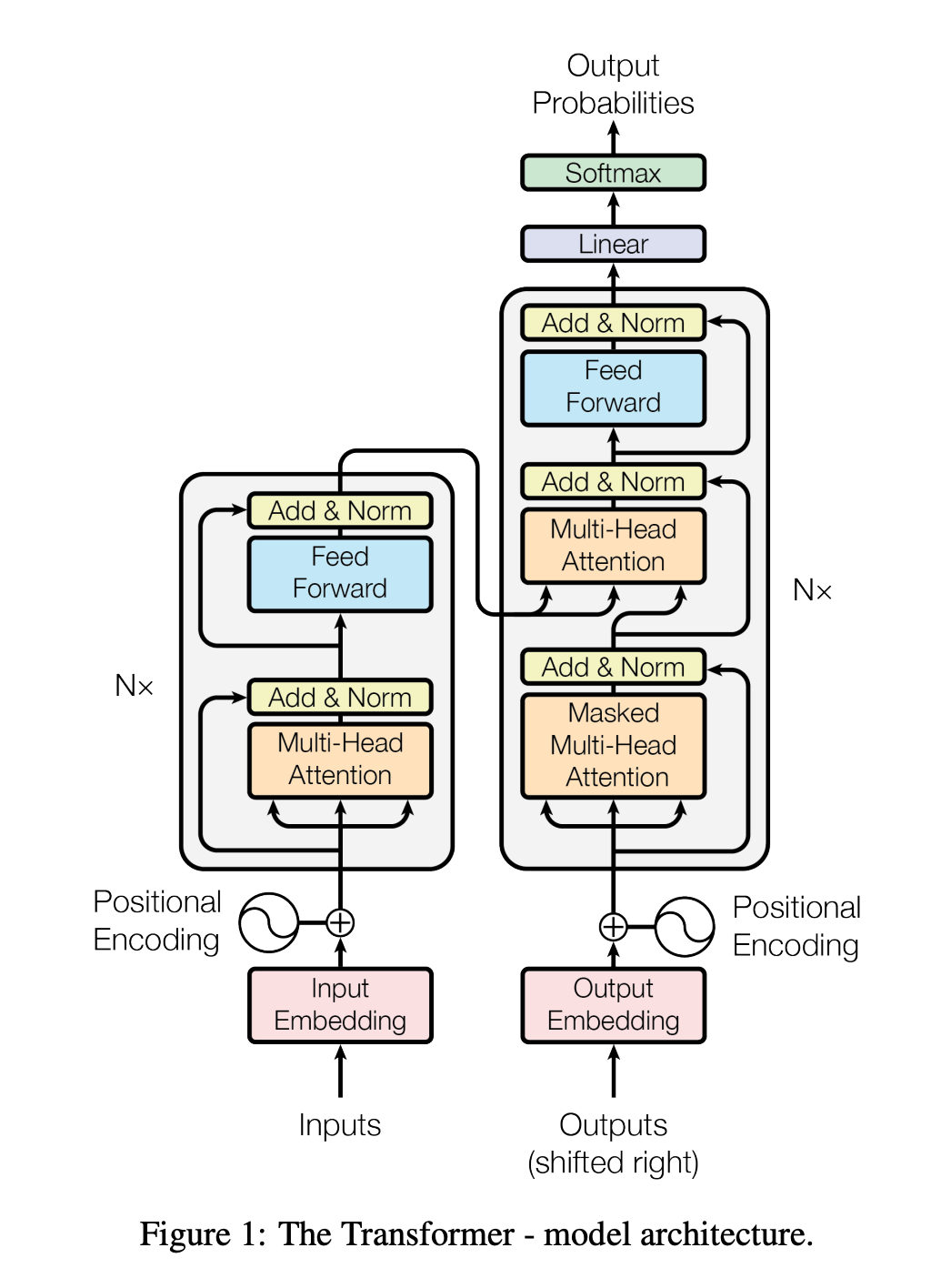
- A very good blog post on the transformers architecture if you are interested in digging deeper: https://daleonai.com/transformers-explained
I hope this was useful, if you want to discuss this further don't hesitate to shoot me an email at mail@yacinemahdid.com !
Have a great week! 👋